Two years ago, when we were still in the prehistoric era of building with LLMs, everyone defaulted to GPT-4. It just worked. An awesome developer experience coupled with a model that is always at the bleeding edge of what’s possible is what catalyzed this boom of rapid AI-enabled apps to be developed and shipped.
Open source models were for those deep in pushing the models to do specific things, but to get the level of intelligence that OpenAI provides via ~2min setup, you needed expensive hardware, time sunk into getting the models running. You couldn’t ship nearly as fast. For all of the AI tinkering that I did, if I had to configure spinning up models I would not have explored the problem space of LLMs nearly as much.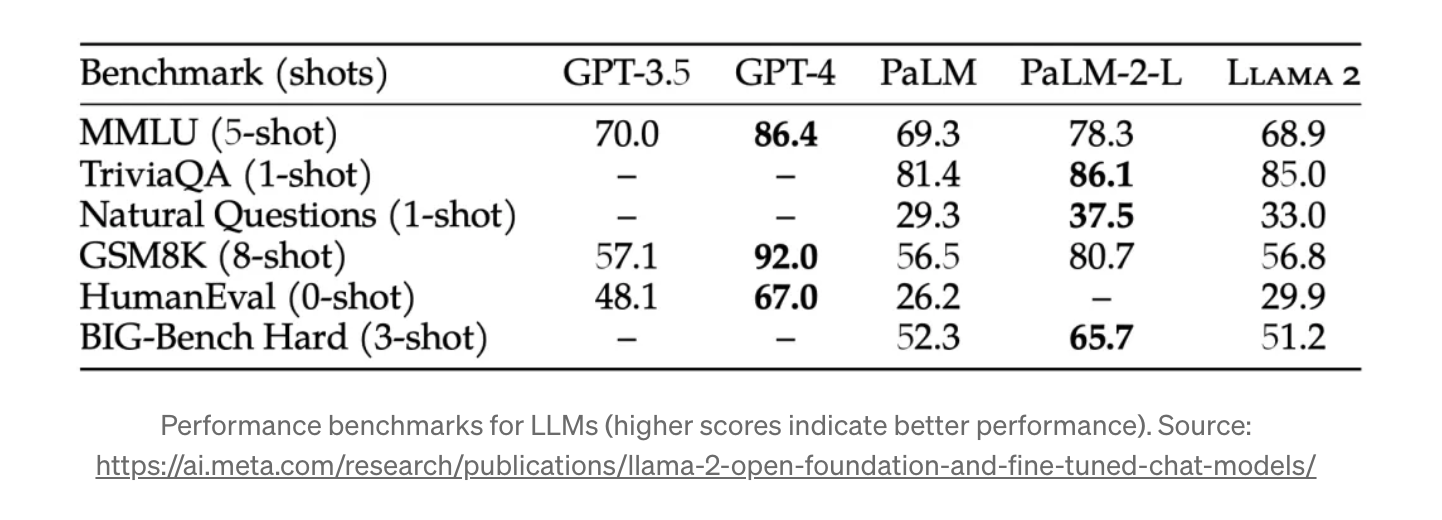
Looking at recent benchmarks, it’s clear that small open source models are now matching or exceeding what was state-of-the-art just a year ago. And they can run on the compute of an iPhone. The economics of whether to rent or own your AI infrastructure is no longer so obvious.
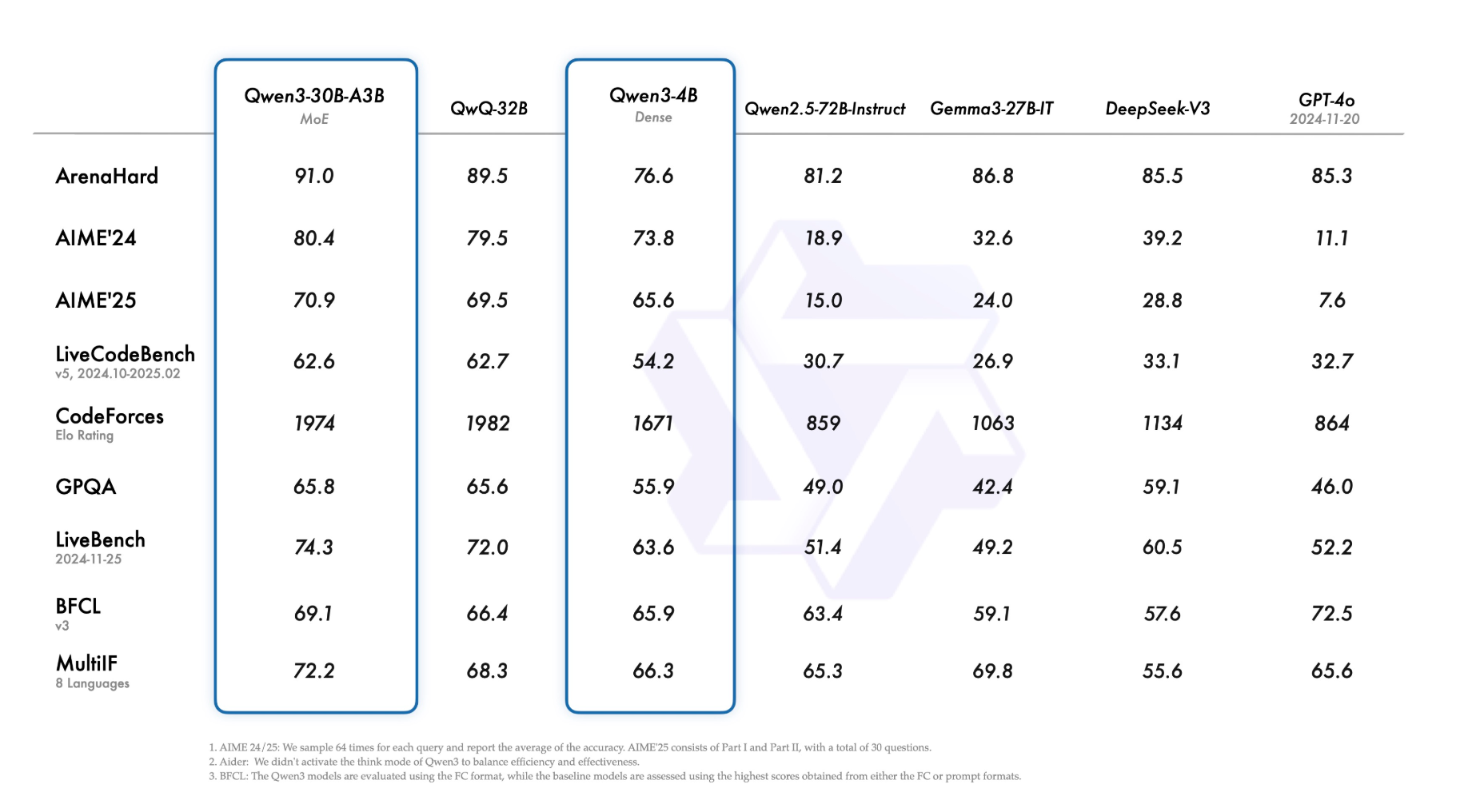
So a 4B parameter model that can run on consumer hardware is outperforming GPT-4o in several key areas. This isn’t to say the frontier models aren’t the best for some tasks, they are. For those that code, I do not see any of us swapping out claude-3.7-sonnet on Cursor until we get claude-4-sonnet. However, the gap has narrowed dramatically for repeatable, well‑outlined tasks. The cost structures for these approaches start to diverge dramatically as you scale up.
The Economics Tokenomics of Choice
There are two paths for deploying AI: the rental model (APIs) and the ownership model (self-hosting). Each has its place, but when you’re running these models over and over for repeatable tasks or investigating breakthrough research are very different things.
Here’s what leading model providers charge:
| Provider/Model | Input Cost (per 1M tokens) | Output Cost (per 1M tokens) | Context Window |
|---|---|---|---|
| OpenAI | |||
| GPT-4.1 | $2.00 | $8.00 | 1M tokens |
| GPT-4.1 mini | $0.40 | $1.60 | 1M tokens |
| GPT-4.1 nano | $0.10 | $0.40 | 1M tokens |
| o3-mini | $1.10 | $4.40 | 200K tokens |
| o1 | $15.00 | $60.00 | 128K tokens |
| Anthropic | |||
| Claude 3.7 Sonnet | $3.00 | $15.00 | 200K tokens |
| Claude 3.5 Haiku | $1.00 | $5.00 | 200K tokens |
| Claude 3 Haiku | $0.25 | $1.25 | 200K tokens |
| Gemini 2.5 Flash (standard) | $0.15 | $0.60 | 1M tokens |
| Gemini 2.5 Flash (thinking) | $0.15 | $3.50 | 1M tokens |
| Gemini 2.0 Flash | $0.10 | $0.40 | 1M tokens |
These prices are perfectly linear (as far as they’re advertised), you pay the same per token whether you use 1 million or 1 billion. It’s worth recognizing you’re not paying for compute alone, but also R&D amortization and profit margins. Sama has to eat too.
At scale, these monthly costs add up:
| Monthly Volume | GPT-4.1 | Claude 3.7 Sonnet | Gemini 2.5 Flash |
|---|---|---|---|
| Low (3M tokens) | $19.50 | $36.00 | $1.46 |
| Medium (30M tokens) | $195.00 | $360.00 | $14.63 |
| High (300M tokens) | $1,950.00 | $3,600.00 | $146.25 |
| Enterprise (3B tokens) | $19,500.00 | $36,000.00 | $1,462.50 |
Token volumes are growing exponentially as companies build more AI applications. What’s 3B tokens today will be 30B next year as AI gets integrated into more systems and processes. Reasoning models (where the model outputs thousands of thinking tokens BEFORE it even responds) further add to this increase.
The Self‑Hosted Option
Last year, the gap between closed and open models was substantial. Today, it’s often a matter of subjective preference which we call ‘vibes’. When we are interacting with LLMs in a multi-turn, conversational format vibes matter! It’s the thing I think we first felt around claude-3-5-sonnet. It was a there was a good UX, and maybe even more of an improvement in the EX (emotional experience?)… its when the LLM just ‘gets’ you.
But when we are building LLM workflows to automate business processes, dont require vibes. These are headless applications running in the background to do one thing over and over again. Here objective cababilities are what to pay attention to.
| Model | Parameters | Architecture | Context Window | Key Strengths |
|---|---|---|---|---|
| Qwen3-235B-A22B | 235B total (22B active) | MoE | 131K tokens | Coding, reasoning capabilities |
| DeepSeek V3 | 671B total (37B active) | MoE | 128K tokens | Math, coding, educational tasks |
| DeepSeek R1 | 671B base (distilled versions available) | MoE | 32K tokens | Reasoning comparable to o1 |
| Llama 3.3 70B | 70B | Dense | 128K tokens | General purpose, multilingual |
Mixture of experts models are what make lots of these effiecency gains possible. They have hundreds of billions of parameters but only activate a small fraction for any given input. (Think - If I ask a question about making banana bread, do I need my East Asian History parameters activated?) This dramatically reduces computation costs while maintaining or even improving performance. DeepSeek V3, for instance, has 671B parameters but only uses 37B at a time.

Further, quantization makes it easier to run substantial models on consumer‑grade hardware or modest cloud instances.
| Model Size | Minimum VRAM (FP16) | With 8‑bit Quantization | With 4‑bit Quantization |
|---|---|---|---|
| 7‑8B models | 16GB | 8GB | 4GB |
| 30‑40B models | 60GB | 30GB | 15GB |
| 70B models | 140GB | 70GB | 35GB |
| 100B+ MoE | ~80GB (active params) | ~40GB | ~20GB |
When people think about running their own models, we think GPU costs, but consider the spent on setting up, maintaining, and improving these systems when new models are coming out monthly. People hours end accounting for 40-60% of your total cost.
This is why smaller teams should start with APIs. Your engineering time is better spent building product. But as you scale, the tokenomics shift. With the right intelligence orchestration (something my company is working on), you can slash that people cost and make self-hosting financially attractive much earlier.
Matching Models to Use Cases
Different tasks require different levels of capability. For many business applications—customer service, content summarization, document retrieval—smaller models now perform extremely well. These are precisely the high‑volume, predictable workloads that benefit most from self‑hosting. As mentioned earlier, coding or investigating new scientific domains still benefit the most from the bleeding-edge models.
For these repeatable workflows, distillation is a particularly useful method which lets you bottle‑feed a smaller, cheaper model with the domain expertise of a frontier‑scale “teacher.”
- Step 1 — Sample: Rent the big model briefly, prompt it with the kinds of inputs your workflow sees, and capture millions of high‑quality Q→A pairs (or function‑call traces).
- Step 2 — Train: Fine‑tune a small (7‑13 B) “student” on that synthetic dataset. The student learns only what matters for your tasks, so it often recovers 90‑95 % of the teacher’s accuracy at a fraction of the compute.
- Step 3 — Serve: Quantize the student (8‑ or 4‑bit) and run it on modest GPUs or even CPUs. The one‑time distillation bill (compute + API calls) is usually paid back in a few weeks once you cross ~40 M tokens/month.
With this approach you own the smarts you care about and keep the rental fees for frontier models reserved for the intense queries.
What This Means for Different Companies
Startups
If you’re a startup, start with APIs. At low volumes (1‑10 million tokens monthly), they make financial sense, and your engineering time is better spent building product.
When you hit about 40‑50 million tokens monthly, look at your usage patterns. If you have specific high‑volume, predictable workloads, that’s where to start self‑hosting.
Mid‑sized Companies
If you’re processing 10‑100 million tokens monthly, you should consider a hybrid approach:
- Self‑host for high‑volume, predictable tasks
- Use APIs for complex reasoning and unpredictable workloads
- Focus on model selection for specific use cases
Analyze your AI usage and identify which workloads could be handled by smaller, self‑hosted models without sacrificing quality.
Enterprises
If you’re processing 100+ million tokens monthly, you can’t afford to ignore the self‑hosting option for at least some of your workloads.
The most effective approach is to implement an orchestration layer that intelligently routes requests to the right model based on requirements. Maintain a portfolio of self‑hosted models for core functionality and reserve API calls for specialized needs.
For an enterprise processing 1 billion tokens monthly (which will soon be the norm, not the exception), the difference between pure API usage and intelligent deployment can easily exceed $5‑10 million annually.
This Isn’t Religious
The question isn’t whether closed or open source models are “better” in some absolute sense. It’s about matching the right model to each task based on capability requirements and usage volume.
The most successful AI strategies treat this as an ongoing optimization problem rather than a one time decision. They start with APIs for flexibility, gradually identify workloads suitable for self‑hosting, and continuously reevaluate as both their needs and the market evolve.
We’ve reached the point where intelligence has become a commodity available in various sizes and price points to match different needs. The companies that thrive will be those that understand this shift and optimize accordingly.